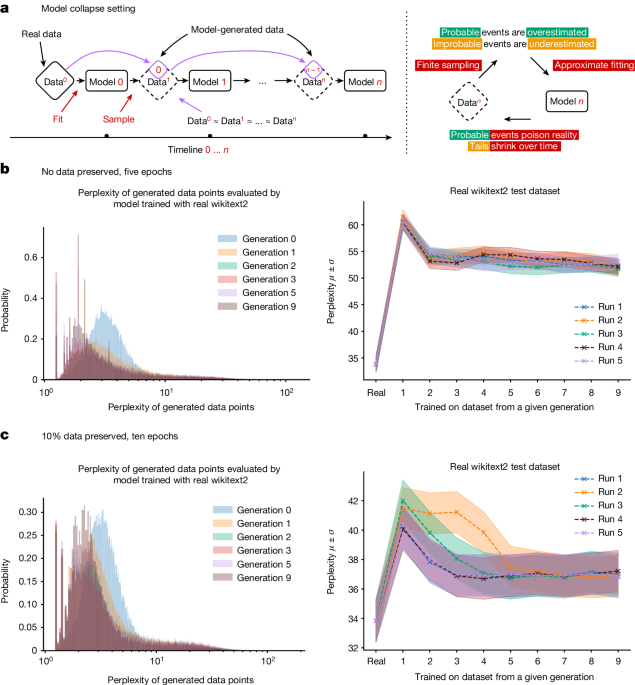
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.

Same thing with Stable Diffusion if you’ve ever used a generated image as an input and repeated the same prompt. You basically get a deep-fried copy.
img2img is not “training” the model. Completely different process.