


A purported leak of 2,500 pages of internal documentation from Google sheds light on how Search, the most powerful arbiter of the internet, operates.
The leaked documents touch on topics like what kind of data Google collects and uses, which sites Google elevates for sensitive topics like elections, how Google handles small websites, and more. Some information in the documents appears to be in conflict with public statements by Google representatives, according to Fishkin and King.
Some information in the documents appears to be in conflict with public statements by Google representatives
I would have never guessed that.
At this point if you are not assuming that corporation is pretty much lying for convenience. you aint operating in reality haha
Yep but I’ll add my two cents, half is lying and half is guessfull ignorance because nobody really knows how big and old systems really work.
No one reaches a position like Google’s without knowing to the atom every knook and crany of their systems.
Eeeeh you overestimate the capacity of people to learn what someone being fired knows
Crazy how self regulation always winds up like this. By crazy I mean predictable of course.
Libertarians assemble!
Listen, the problem is too many regulations prevented the Invisible Hand from manifesting. If we remove even more regulations the free market will work this time, I swear.
Libertarians go away!
I prefer socialist libertarian.
You’re supposed to move to a different search engine for the market to work. I already have, have you?
This approach is doomed to fail, so long as the general public isn’t aware of the problem or its scale. Government regulation is the only way.
It’s enough if an alternative reached even 1%. That would still be billions of searches a year, enough to keep them running
I did years ago when Google started censoring my search results even with safe search off.
Unfortunately Bing is doing it too now and I can’t find a search engine that isn’t, though I would love to learn about one that isn’t.
This is the issue. they’re all shit. Even kagi often fails to deliver useful results. Its the best of the bunch but AFAIK their own crawler is very reliant on google.
I tried using some but they’re all equally shit.
This doesn’t have anything to with regulation. This is mainly a bunch of SEO and marketing people whining that Google hasn’t been honest with them in telling them exactly how to game their search engine.
Well I am just shocked, SHOCKED. Well, not that shocked.
Here is an alternative Piped link(s):
Piped is a privacy-respecting open-source alternative frontend to YouTube.
I’m open-source; check me out at GitHub.
Can’t wait for selfhosted web search to become better.
You mean hosting your own crawler/indexer? That doesn’t really sound like a thing you could do cost-effectively.
No problem we crowdsource the crawling torrent style.
We outsourced that to google for reasonnable performance reason. But they shit the bed so now there’s no choice but to do it ourselves.
ooh that might be an interesting app to run on veilid
What is that and how does it apply ?
Veilid is a peer-to-peer network and application framework released by the Cult of the Dead Cow on August 11, 2023, at DEF CON 31.[1][2][3][4] Described by its authors as “like Tor, but for apps”,[5] it is written in Rust, and runs on Linux, macOS, Windows, Android, iOS,[6] and in-browser WASM.[7] VeilidChat is a secure messaging application built on Veilid.[1][4]
Veilid borrows from both the Tor anonymising router and the InterPlanetary File System (IPFS), to offer encrypted and anonymous peer-to-peer connection using a 256-bit public key as the only visible ID. Even details such as IP addresses are hidden.[4]
Surprisingly, it’s very doable, requires basic technical knowledge and relatively minimal computing resources (runs in the background on your computer).
I have tampermonkey script that sends yacy to crawl any websites that I visit, and it’s keeping up relatively good index for personal use of the visited websites. Combine yacy with ~300gb of Kiwix databases, add searxng as a frontend and you have pretty strong self hosted search engine.
Of course you need to supplement your searches from other search engines, as yacy does not crawl the whole web, just what you tell it to.
I encourage anyone who’s even slightly interested on this stuff to try Yacy, it’s ancient piece of software, but it still works very well and is not an abandoned project yet!
–
I personally use Yacy mostly on private mode, but it does have the distributed network there as well.
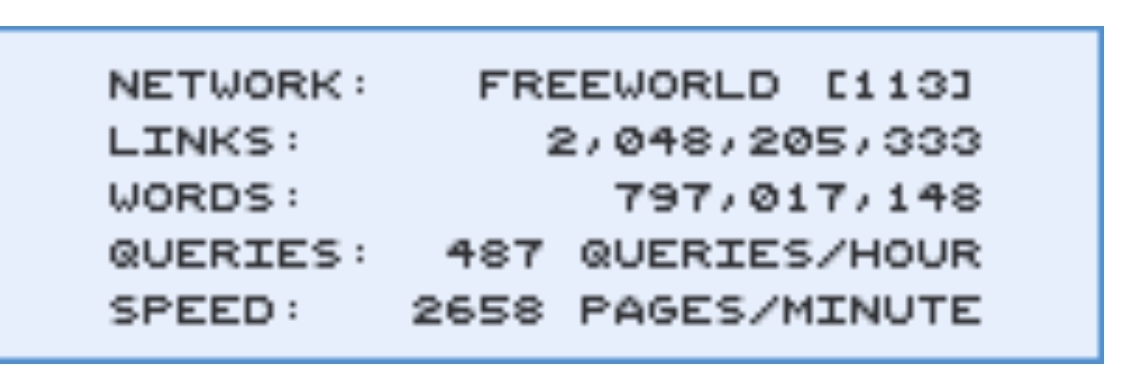
Yeah, I guess the P2P component sort of solves part of the issue I was imagining by distributing indexes and crawling. I was thinking that people were trying to run all of Google on a raspberry pi at home.
This is interesting, have you had it index reddit? I’m just wondering how much storage space the database takes up.
Hi!
Great question! I don’t crawl reddit, but this applies to other large sites as well. reddit themselves they have at this very moment banned the ip range where I host my Yacy at (Hetzner). I just looked up from my index that I do have 257k pages indexed from reddit through teddit I used to run, this is from before reddit api-enshittification, going to delete those right now.
And the way how the crawling is done is you define crawling depth, which limits how much content is crawled from the site.
- 0 crawling depth = only the page you send Yacy to, nothing more.
- 1 crawling depth = all the links on the page you send Yacy to
- 2 crawling depth = all links on the page you send Yacy to, and all links on the pages crawled…
- 3 …
- n …
… etc.
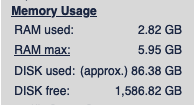
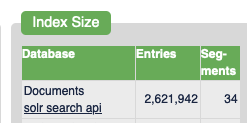
I have my tampermonkey scripts set to only crawling depth of 1 at the moment (Just set them to 2 actually, kinda curious how much more I will be crawling), I’ve manually crawled some local news sites as a curiosity at the beginning. And my database is currently relatively small, only around ~86.38 gigabytes according to Yacy. This stores aproximately 2.6 million documents in Yacy’s Solr.
–
Yacy has tons of options for crawling, so you can customize how much it crawls and even filter out overly large sites with maximum number of documents set when you send Yacy there.
Large picture of Yacy's interface for starting a crawl.

–
The tampermonkey script I’ve been talking about in these posts, it’s very simple script: https://github.com/JeremyRand/YaCyIndexerGreasemonkey
Hit me up if you guys have more questions! I’m by no means an expert on Yacy, but I will do my best to answer.
Right!
Before his company was able to block more of Microsoft’s own tracking scripts, DuckDuckGo CEO and founder Gabriel Weinberg explained in a Reddit reply why firms like his weren’t going the full DIY route:
“… [W]e source most of our traditional links and images privately from Bing … Really only two companies (Google and Microsoft) have a high-quality global web link index (because I believe it costs upwards of a billion dollars a year to do), and so literally every other global search engine needs to bootstrap with one or both of them to provide a mainstream search product. The same is true for maps btw – only the biggest companies can similarly afford to put satellites up and send ground cars to take streetview pictures of every neighborhood.”
Federated bookmarks?
Federated directories. We’re going back to Yahoo like it’s 1995
Webrings!!!
<under_construction.gif>
Uh…I know we’re all just having fun here, but I need to be part of a webring again. If anyone is more than joking, I kinda need to know about it. Thanks.
there are tons of webring still going these days!
Seriously? Cool. I’m going to go do some research then. And maybe entirely change the purpose of my blog, just to fit into one…
I loved Geocities!
Neocities is trying to be a modern reincarnation https://neocities.org/
I mistook that as neopets
Yahoo patiently plotting its return from Japan.
I’m so ready for something like this. I’ve cleaned up my bookmarks and been waiting for alternatives to search engines.
You could use Common Crawl, it’s run by a non profit
Look up the yacy repo in github
How is that even supposed to work? These search engines need per definition massive databanks to search through. Either you need your own crawler and indexer which is more than just inefficient, or you are limited to a relatively short list of curated static results.
If they’re taking tips from Google, why would they get better?
Google actually was good, so there’s probably some good information in this documentation. If nothing else we can perhaps figure out what “went wrong.”
Edit: I’ve been reading the blog post that appears to be the main person the leak was shared with and there’s a lot of in-depth analysis being done there, but I’m not seeing a link to the actual documents. This is a huge article, though, I might be overlooking it.
That was an interesting read. Thanks for linking to it.
What are the current contenders?
What it looks like beyond Google and Bing
It would be much harder to know what exists beyond “GBY” (Google, Bing, Yandex) and how it all works without the work of Rohan “Seirdy” Kumar. For three years, Kumar has been updating a heavily annotated list of search engines with their own indexes. It is 7,000 words, but only a portion of it deals with engines offering general indexing, in the English language. You can read Kumar’s evaluation methodology for a better understanding of how he compared and assessed sites.
What stands out? Mojeek (“it’s not bad… I’d live”) and Stract (“a useful supplement to more major engines”) are two of Kumar’s favorites. Right Dao has “very fast, good results,” in part because its crawler starts off from Wikipedia. Yep reaches farther out, showing results that link to and back from sites related to your query and also promises to share ad revenue with creators. All of them show promise, but you get the sense that they’re a second car, or a third bicycle, rather than a primary transport.
There are far smaller-scoped engines in other sections of Kumar’s post. If you’re wondering where that one other search engine you’ve heard about is, it’s probably in the “Semi-independent indexes” section, because it uses a GBY index when its own results are not strong enough. Here, you’ll find cryptocurrency-friendly, controversy-courting-founder-having Brave, a few engines that either “resell” GBY results or stuff affiliate links into them, and “the most interesting entry,” according to Kumar, Kagi.
Kagi requires an account and uses its own index, Teclis, in combination with Google, Bing, Yandex, Mojeek, and others, including, notably, Brave. Kagi’s founder has strong opinions on the AI-based future of search and responding to harmful searches in ways that are not “scalable.” How much of that does or does not bother you will vary, but it’s worth noting that Kagi also suffers when the GBY triumvirate is restricted.
Ars Technica this week: Bing outage shows just how little competition Google search really has
The referenced search engine comparison by Rohan “Seirdy” Kumar
can’t emphasise too much that this piece is a very necessary read for anyone who wants to know about search; not just because it says good things about us, but because of the depth of research which has been put in here. Most times you encounter an article about indexes they are just taking whatever a (meta)search engine says about themselves, not even looking at privacy policies for “relationships with microsoft” etc. or doing any comparative work.
I’ve been using Kagi and really like it so far. It’s not good for local stuff, but afaik only Google and Bing have the resources and userbase for things like maps and reviews. It’s designed to be an ad-free ‘premium’ search engine and only earns revenue from users paying for membership.
OpenStreetMap’s platform is the only real way to compete against Google and Apple and it’s why Microsoft even though it has Bing Maps, has licenced to them resources like satellite imagery for mapping. It’s awesome in bigger population areas but there’s still a lot to map in rural places outside the EU.
Review is harder. Right now the leading open platform afaik is Open Reviews (aka Mangrove Reviews) which has tie-ins to OSM projects like MapComplete. OsmAnd and OrganicMaps have open tickets to hook into that ecosystem. You’re right about the userbase problem though, I think it (or a successor) needs AP federation to really take off. That being said there’s several active non-Google nonfree alternatives like Yelp and TripAdvisor as well as niche sites for things like camping, parks, and schools.
the only one I know that isn’t a proxy search is yacy
I was looking at it the other day unfortunatly its got quite poor results
That tracks
YaCy, Mwmbl, Alexandria, Stract, Marginalia to name a few.
Google has been pretty crap for a decade now.
I still remember demoing how easily they can manipulate people by searching “Pakistan News” and the results being exclusively all Indian media outlet propaganda way back in 2016.
I really feel like they never got properly exposed for this just because it’s a search engine and not a social media, so people didn’t care enough about it. Also because Google was still top of the game in most results compared to other sites back then.
My thought exactly. If this was back in like 2010, it would be a real oh shit moment, The key to the kingdom has been leaked. Now I don’t think anybody really cares other than SEO spammers who will game the system even more than they already are.
Google search is crap and has been crap for some time. Not sure any others are better. But it started going downhill with the Google Plus social network, when they removed “+” as a search operator so you could better search for ‘Google+’ that was the first time they messed with Search to further some other business goal. It wasn’t the last time. Back when Google was good, they publicly said their goal was to get you off their site as fast as possible. Now the results reek of engagement algorithm bullshit.
SearXNG works all right for me, and it’s free. I’ve also heard good things about the paid service Kagi.
Rand Fishkin, who worked in SEO for more than a decade, says a source shared 2,500 pages of documents with him with the hopes that reporting on the leak would counter the “lies” that Google employees had shared about how the search algorithm works.
Am I supposed to care that the poor SEO assholes that need to get their ads more visibility weren’t being given all the instructions on how to do that by the search engine?
Most of this article is SEO “experts” complaining that some of the guidelines they were given didn’t match what’s in the internal documents.
Google is shit, but SEO is a cancer too. I can’t be too bothered by Google jacking them around a bit.
And I supposed to care that the poor SEO assholes that need to get their ads more visibility weren’t being given all the instructions on how to do that by the search engine?
No. You’re supposed to care that a company is pointlessly* lying, thus it’s extremely likely to deceive, mislead and lie when it gets some benefit out of it.
In other words: SEO arseholes can ligma, Google is lying to you and me too.
*I say “pointlessly” because not disclosing info would achieve practically the same result as lying.
need to get their ads more visibility
I occasionally encounter the desire for a search engine to surface non-advertisement content :)
Now if they lied to advertisers and told small bloggers, reputable news agencies, fediverse admins, etc. the insider secrets… now we’re talkin’!
Historically, Google had a give-and-take with SEO. You can’t make SEO companies go away, but you can curb the worst behavior. Google used to punish bad behavior with a poor listing, and you had to do some work to get it back into compliance and tell Google it’s fixed up.
It wasn’t ideal, but it functioned well enough.
The drive to make search more profitable over the past few years seems to have meant dropping this. SEO companies can get away with whatever. If they now have the whole manual, game over. Google of a decade ago might have done something about it. Google of today won’t bother.
Edit: If you’re going to downvote me, please take the time to explain why you think I’m wrong. Stop being the hive mind.
Tell me you don’t know shit about SEO without telling me you don’t know shit about SEO.
Just because there are people who do bad things doesn’t mean the industry is bad or have bad intentions. SEO isn’t ads. Advertorials can be a tactic of SEO, but it’s not SEO as a whole. Same with clickbait because it works, and I guarantee you also fall for it constantly.
SEO is about understanding what someone needs and creating an experience to ensure that someone finds the answer to what they need through content and/or a product to solve their needs.
This can be achieved through copywriting, researching search trends and queries, technical analysis of websites and how they render, providing guidance on helpful assets (photos, pdfs, videos, form, copy, etc), PR outreach because links are how people move around online or discover things, social planning because social media are a form of search engines, and more.
And finally, SEOs are not responsible for how Google treats shit. That’s Google who is responsible. Google is the one that tweaks the algorithm and doesn’t catch spammy shit. In fact many SEOs catch it and report it to Google’s reps, but they are the ones who can ensure the right team(s) fix the issue.
Fuck SEOs - that is why you are getting downvoted. Organic content creation has been ruined by you AND google. Own your problems, beg forgiveness, stop playing the stupid game where there are no winners
You’re exactly the person I was talking about - the hive mind. You don’t critically think and you blame an entire industry that has niches and actors of all sorts. You’d probably say all black people are bad because a few on a street did something wrong once.
Please, tell me YOUR industry so I can have fun shitting on it and drawing asinine conclusions.
Worked with more than a few SEOs. Software developer here.
I’m sorry you’ve had bad experiences. There are a lot of bad SEOs, but there are a lot of good ones. I’ve worked with a lot of shitty developers as well.
Would it be fair of me to blame software developers for the likes of Microsoft, Google, Meta, Amazon, or poorly implemented Wordpress pages where links get hijacked and redirected to spam? Or those that use AI to write code? Or for slapping resource on top of resource to slow down pages and bandaid shitty spaghetti code?
Edit: or pushing out half baked bullshit that breaks or has a ton of holes? As if the software development industry isn’t responsible for coding worms, trackers, or other malicious stuff. So many hacks/charlatans in software development too.
Yup, blame away, but also recognise lots of good that they have done too. Open Source, the fediverse, medical software, communications software. To name but a few. What good have SEOs ever done?
Positioning non profits, government agencies, and more competitively in results. Even Google gets outranked for their own keywords.
User experience and flow for many companies that don’t have these people, suggesting content topics to solve questions, ensuring that sites are found/rendering correctly and pointing out/fixing developer fuck ups, creating accessibility (markup suggestions and alt text), finding ways to compete with competitors.
Don’t confuse content and marketing with SEO. Many of them don’t listen to us anyway.
wait what is “social planning” and how is it different from conventional marketing on social media. That seems pretty far removed from search engines
Great question! Search engines crawl social media and discover links. It can be a sign of trust and authority if it’s shared widely, which can help boost signals of page importance to Google (or other engines) and help with pushing up in organic ranking positions.
Harmonizing brand details (name, address, phone number, website link) across all social platforms is important so you don’t send mixed signals or lead to unneeded redirects.
There’s also figuring out what page(s) you want to ensure are showcased if multiple URL links are allowed or maybe your social team doesn’t know all of the page assets you have to satisfy their audience, such as an orphaned page. These are part of what are called “backlinks”.
Hashtags do matter for some platforms and knowing how to research them for intent is wise.
There’s also open graph (OG) metadata that you can set on a webpage that allows your metadata to be different on social platforms than you would use for a search engine - tailor to your audience!
Edit: one other thing is, while not social media, maybe connecting with a social team (if there is one) to find out if any posts need to be applied to Google Business listings via a Google Post for local locations.
Here’s the sooper-secret search result algorithm for whatever you type into Google:
YouTube results, followed by Reddit results, followed by “Sponsored” results, followed by AI-written Bot results, then a couple pages of Amazon results and finally, on page 10 or so, a ten-year-old result that’s probably no longer relevant.
That’s generally what I’ve found to be the case, shocking that it’s considered so secret lol
awesome, now we can make our own search engine that is filled with complete trash and isn’t concerned with helping the user at all.
I want a federated social bookmarking site. Not for news or discussion of recent stuff, but to keep some good sites in your account and to share with others.
Searching those and getting results with attached upvotes/downvotes would be ideal
Interesting concept. Like if you could upvote/downvoted the SERP and it actually mattered and wasn’t easy to manipulate.
Was going to say that I was dreaming of such platform, but then it can be used for more than just links, and work as a decentralized Usenet, and what’s more important, as a rating system potentially more resilient to abuse (by bots or by people whose votes you don’t care about). Then noticed that you wrote “federated”.
You can deferate low quality instances and mods of instances can ban bots that upvote spam
Each instance can have its own theme, like an anime instance that just moderates anime content and can’t possibly make judgements on whether the physics content is of high quality
So you want Reddit? We have a federated clone of that. It’s Lemmy.
I don’t want the latest links, in fact there should be no feed, only search and directories
Now, where to download these, for science.
Use Bing 😅😅
Google it.
Where can one get a hold of these documents?
This appears to be the original blog post, but I’m not finding a way to download this. https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
Is this not leaked past this one person?
Edit 2: No, these appear to be normal public docs.
Edit: seems these are the docs? https://hexdocs.pm/google_api_content_warehouse/0.4.0/GoogleApi.ContentWarehouse.V1.Model.QualityNavboostCrapsCrapsData.html
Grab it while it’s still up: https://github.com/yoshi-code-bot/elixir-google-api/commit/d7a637f4391b2174a2cf43ee11e6577a204a161e
Wait why is that commit still up if this is a data leak?
It’s not a data leak, it’s a a leak of internal documentation in a google api client which supposedly contains “leaks” of how the google algorithm might works, e.g. the existence of domain authority attribute that google denied for years. I haven’t actually dig in to see if its really a leak or was overblown though.
Internal documentation leaking is still a data leak, it’s just a subset of a data leak.
If it was sensitive information that commit would have been purged by now. The original PR (on the Google Clients repo) has no mention of problems, and there are no issues of discussions around rewriting the git history on that item.
This makes me think this isn’t actually a problem.
My org is less practiced on operational security than Google and we would purge that information within minutes of any of us hearing about it. And this has been on blog posts for a while now.
I guess we are going to be in for more SEO spam than usual if this document is accurate. But I think its good that we are finally going to get a better understanding how Google manipulates people with the algorithm.
So a win-lose situation.
More seo spam? What isn’t already?
Yeah, what isn’t SEO spam—Search Engine Optimization spam, SEO marketing, keyword stuffing, Google keyword stuffing, backlink building, best backlinks, best backlinks for backlink building
Heh. Now I can look forward to a new browser plugin that automatically jumps to the first page of Google results that contains any entry that isn’t a Viagra ad. Huge time saver!
Who wants to take bets that Search itself ends up in The Graveyard soon, leaving nothing but the new AI abomination in place?
I could see them not letting you directly search anymore, only through the LLM bot. Because that’s been how things have been going anyway, Google seems to fully ignore literal searches with quote marks now, presumably because it doesn’t fit their vision of using natural (imprecise) language. So why not make the LLM write the search query for you in a completely opaque way?
You can search, it will just cost you $15/mo for the Google battlepass.
More likely they will just slowly rebrand search to more AI type things. Then slowly retire the non-AI parts in the background.
Yeah, I know a lot of the smaller, independent search engines are lacking, but the people using the “udm=14” trick to remove Google’s AI results now, as if that won’t be removed as soon as Google needs to show investors the AI is more profitable.
the url needs a param to tell the server what kind of query is being requested. as long as they have the ‘web’ tab and option, it will be there. but i’m guessing they will come up with a way to encode that instruction in the tracking bits or something so you can’t just manually tack something on to the end of your query url and bypass their precious a.i. bot
Honestly I hope this bites them hard. They’ve done way way worse to small businesses and competition for decades now.
It’s honestly quite strange that this sort of black box system is allowed to exist. How are governments around the world OK with a vast majority of the internet being filtered through a private company’s lens without any sort of insight into how it works? That sounds skeevy as shit.
Better than those governments having control. Ideal scenario is everything is decentralized
Why is that better? It may not be ideal but governments have at least some accountability.
Because that paves a very easy path to corruption . No freaking way do i wanna live in a country where the government has absolute control over all information spread.
Don’t get me wrong, fuck Google, but government control of the Internet just sounds worse
What makes governments any more susceptible to corruption than a private organization?
I’m not actually talking about governments having absolute control. That’s a pretty extreme scenario to jump to from from the question of if it’s better for a private company or a government to control search.
Right now we think Google is misusing that data. We can’t even get information on it without a leak. The government has a flawed FOIA system but Google has nothing of the sort. The only way we’re protected from corruption at Google (and historically speaking several other large private organization) is when the government steps in and stops them.
Governments often handle corruption poorly but I can rattle of many cases where governments managed to reduce corruption on their own (ie without requiring a revolution). In many cases the source of that corruption was large private organizations.
You make some good points. But consider this. This data was publicly leaked by hackers. These hackers, if we go by precedent, will probably get away Scott free. sure it was very difficult to find this data, but not impossible. On the other hand a government if faced with a breach like this, would probably find the hackers and detain them as threats to national security, as we’ve seen with Edward Snowden.
Though our system isn’t perfect, i think that having a corrupt Google is better than a corrupt government in this case. As you said, Google can be corrupt, but the government can step in and take over, whereas, if a government decides that it’s access to citizens data is important enough, they can continue with corruption with less resistance. I mean, who guards the guards right?
FOIA requests generally don’t involve hackers or leaks. The act exists because citizens insisted that government provides visibility into its inner workings.
What is the equivalent for Google, or any other private company?
Did you notice the US President from 16 to 20?
Even after felony convictions, there is no accountability or consequences.
Have you seen the US Supreme Court?
Don’t tell me a government has any accountability when minds are twisted by misinformation engines like Fox & Friends.
Not that a company is any better, yet alone google.
It’s hard to draw meaningful conclusions form a single 4 year period. There have been several instances of corruption (and significant externalized costs) in private firms that went on for much longer than 4 years.
I agree that there is a lot of corruption in government but there’s a long gap between that and no accountability. We see various forms of government accountability on a regular basis; politicians lose elections, they get recalled, and they sometimes even get incarcerated. We also have multiple systems designed to allow any citizen to influence government.
None of these systems and safeguards are anywhere close to perfect but it must be better than organizations that don’t even have these systems in the first place.
I agree decentralized is better, but isn’t that an argument in favor of a government having more control than a corporation?
No? What I said was “better than governments have control” how is that pro government?
you said “ideal scenario is everything is decentralized”
would it be right to assume “more decentralization is better”?
if so, then which is more decentralized: a corporation or a government
yes, what you said was paradoxical, which is why i was saying “it’s actually in favor of government”
Ahh, I suppose I could see that
No it’s not better.
Do you have any sort of argument for that or is it just thoughts different, different thoughts bad?
I tried to cry for them but after Googling instructions about how to I poured Elmer’s Wood Glue on both eyes. I cannot call the result tears. Not sure what to call it, but certainly not tears.
Someone got a torrent for us?
I haven’t checked but its probably on postman on i2p






















